If you’ve worked on building the information architecture for a website or app, you’ve probably encountered some items that were a bit tricky. It might be that they had several natural homes (polyhierarchy) or they fitted loosely into a single category. You’ve probably wondered how to handle this situation, asking yourself if you should create some specific subcategories for these odd items or just put them in the categories that they sort of belong to. You might have even thought about it in terms of how “strict” or “logical” your categorization needs to be.
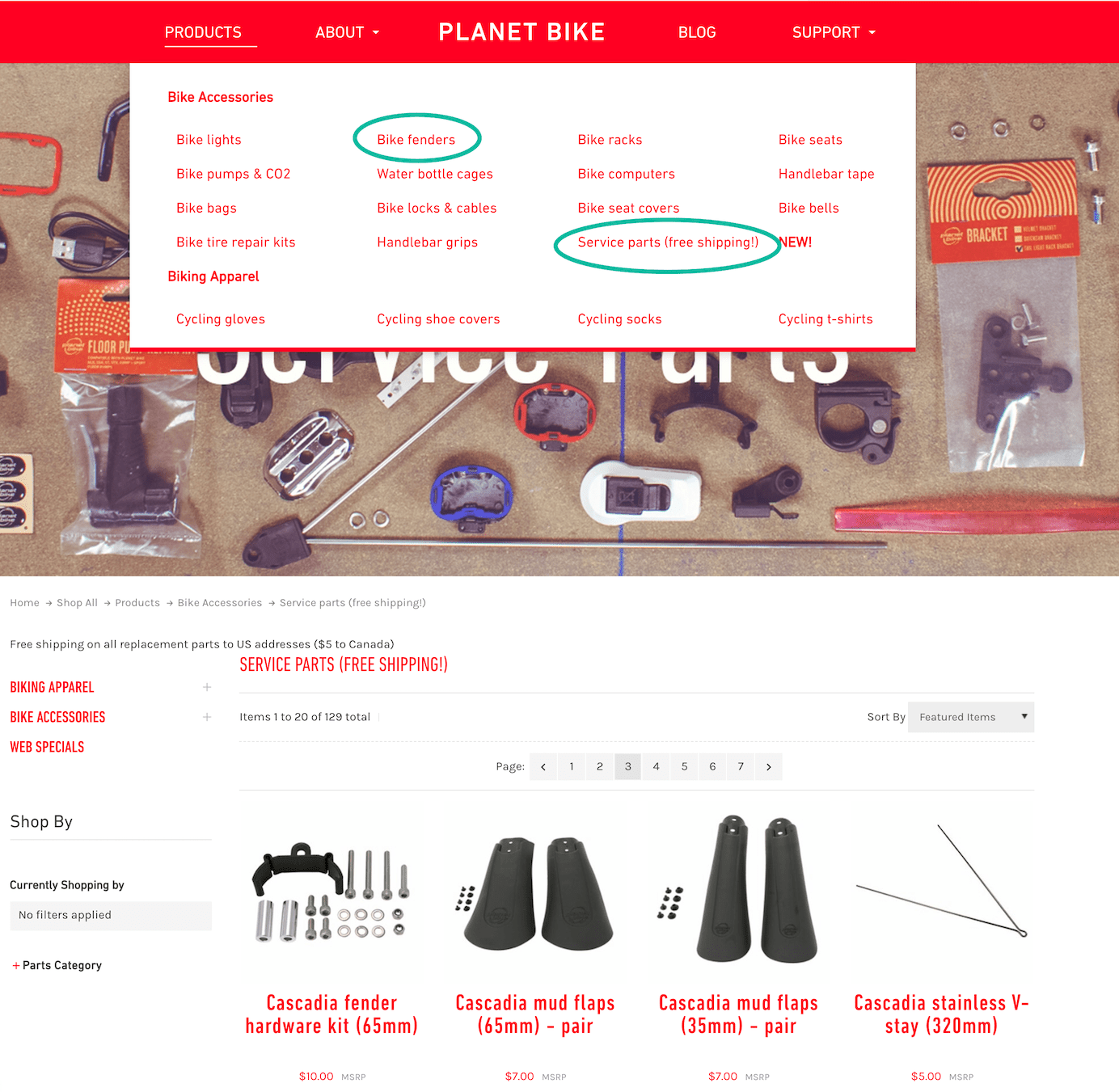
Information architects often struggle with how similar things need to be in order to belong to the same category and, conversely, how different they should be in order to be split apart.
Card Sorts Reveal Unexpected Groupings
Card sorting is a commonly used research method for information-architecture projects. It involves asking users to group objects (cards) into piles that make sense to them. The idea is that if a large percentage of people assign an object to the same pile (or category), then the object can be safely put in that category in the final information architecture.
Analyzing card-sort data is often challenging. First, there’s a fair amount of variation from one participant to another.
And, second, we often end up with outlier cards –- that don’t fit cleanly into the schema that our users largely agree upon.
Most often, card sorting indicates a loosely related category for outliers –- but the assignment to that category is relatively weak compared with that of other items in it. (In other words, some participants may have voted to assign the outlier to the category, but not as many as for other items in that category.) In such cases, information architects need to decide whether the outliers should belong (1) to the main category they’re weakly associated with (possibly as a dedicated subcategory of their own) or, (2) to an entirely separate category of their own (or both).
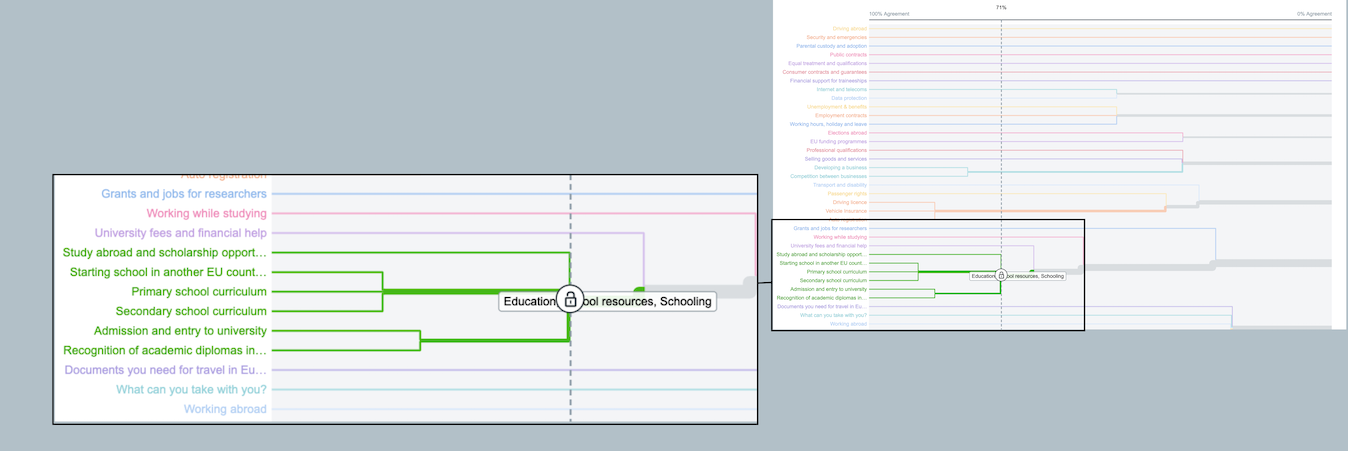
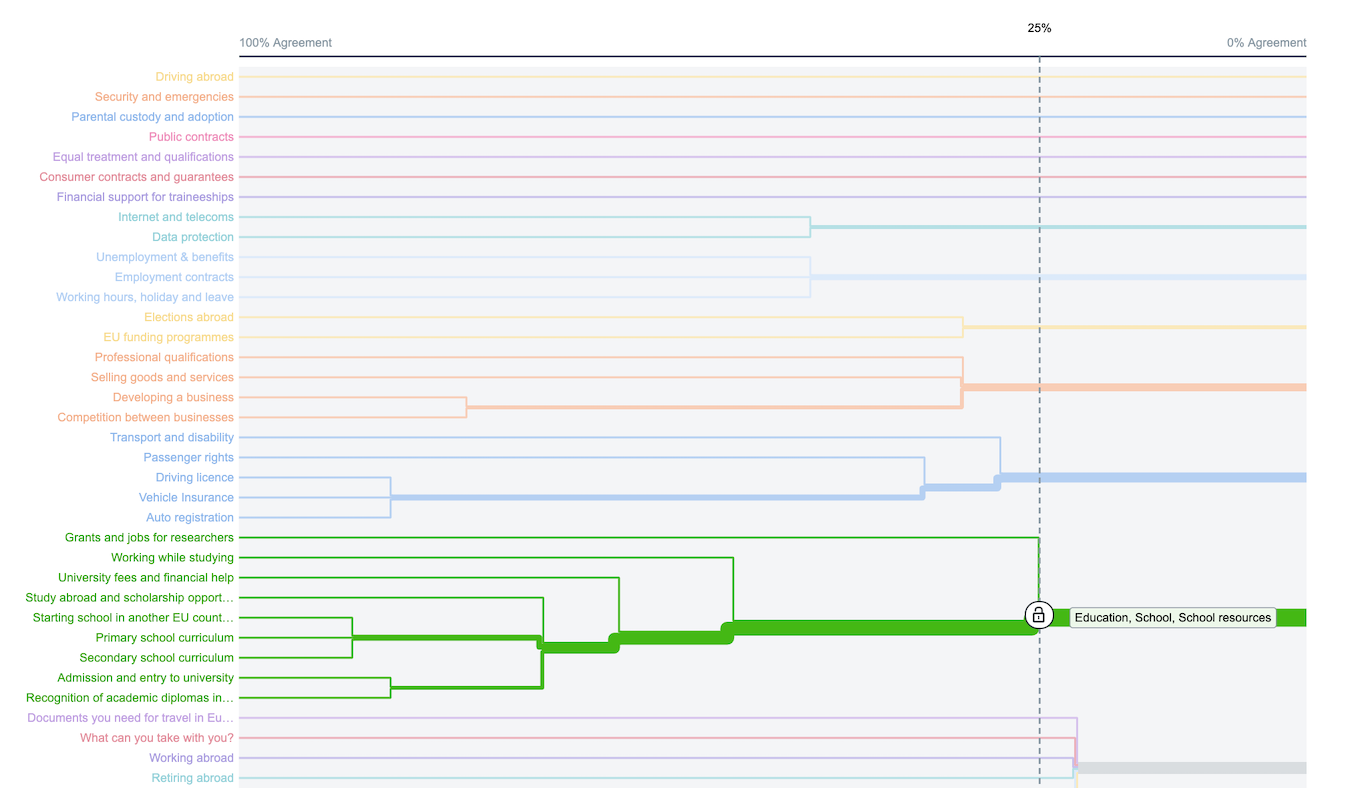
Sometimes, it is a question of whether to create a subcategory for just one or two items that are a little bit different than the other items. In other cases, we will find that our study participants put together very surprising collections of things that don’t fit our expectations at all.

The information architect here must make a subtly different decision than in the education example: since Flora and Fauna are conceptually a little different than the other items in this group (which are associated with tourism and cultural attractions), the choices become:
- Put all these items in a single category (e.g., Things to Do, Visiting the EU) with no subcategories and hope that people interested in local plants and animals will look for that information here.
- Have that same overarching broad category (like Things to Do), but either
- divide the content into subcategories for Culture and Outdoor, or
- leave most things in the main category and just put Flora and Fauna into a subcategory.
- Have a single top-level category for Culture and a separate one for Outdoors.
- Crosslist things in multiple categories (a form of light polyhierarchy).
So, what should an information architect do?
Categorization Theory: Humans Aren’t (Strictly) Rational
When figuring out what to do about category outliers, it’s worth backing up and understanding what happens when people group things together.
First, allow me to disabuse you of the common assumption that people develop firm, logical boundaries between categories and that those firm boundaries are defined by common properties of all the items that got grouped together. This implicit assumption is logical; however, it is not true. (I’m not talking here about the formal categorization and definition setting that comes up in science, law, and the like, but about the intuitive categorization that our users rely on in their mental models.)
For example, what constitutes science fiction? Is it, like the name suggests, related to science? Obviously, it’s not based on science — Star Wars, though a lot of fun, constantly breaks the rules of physics as we know them. Is it set in the future? Battlestar Galactica is a great counterexample (so is Star Wars, for that matter). Space-based? Nope, N.K. Jemisin’s Broken Earth Trilogy dispels that assumption. And so on.
So, how do people form categories? Linguists and cognitive scientists have come to models that revolve around the concept of family resemblance. Family members certainly have some shared characteristics (facial features, likes and dislikes, etc.), but not all members of the family have the same characteristics. Family resemblance is by degrees and there is inherently a spectrum for each characteristic that family members have in common, rather than a binary yes/no.
Furthermore, people frequently add new items to a category and extend its boundaries, even though these new items are different than the other established category members. Famously, the category of games got a big shift in its boundaries when video games first arrived in the 1970s. Thus, members of a category don’t all have to have a single, fixed set of shared characteristics.
Another critical concept is that of central and noncentral category members. People consider some category members to be better exemplars of the overall category than others. If I wanted to teach an alien what a car is and I showed them a picture of the popemobile, you might laugh and think I am not a very good teacher. But you would almost certainly agree that the popemobile is a car — yet, an odd, atypical one. Noncentral category members are still relatively easily recognizable as members of their categories, but not as easily recognizable as other central members of the same category. That’s the key distinction — noncentral category members can still belong to the category, even if they aren’t the best examples of it.

Interestingly, just because something is a noncentral category member conceptually, doesn’t mean it’s not popular –- for example, in 2020, in the United States, the best-selling car was the Ford F-series pickup truck. A pickup truck is not a central category member for the conceptual category car, but the Ford outsold the Toyota Camry (a rather central member of the category car by nearly anyone’s intuitive sense) by 91%!
So, let’s go back to how to handle outlier problems in information architecture. We’ll make these decisions largely from a qualitative standpoint –- what makes the most sense, rather than worrying too much about the differences in percentages obtained from a card sort. It’s also important that our decisions be heavily influenced by business priorities. If something that might conceptually live deeper in a hierarchy matters a lot to the business or to users, we might choose to surface it up to a higher level in the hierarchy to increase its visibility.
Approach 1: Place Outliers in Subcategories in Navigation
One approach is to create a more-specific subcategory dedicated to the outliers we identified. This approach has the advantage that people seeking out very specific items could filter down the list of items they need to consider.
In this case, we essentially isolate the noncentral category members from the rest of the group. This approach makes the most sense when the outliers have relatively low degrees of family resemblance to the larger category. Including them would force us to use a more generic category name, with low information scent. To come back to the EU-visitor website example from earlier, if we took Flora and Fauna and put it in the same main category with cultural and historical attractions, we might need to use a name like Things to Do, which has lower information scent than Culture.
Beside lowering information scent for the parent category, the other downside to this approach is that it may result in a deep information architecture, with lots of subcategories for users to consider (and some of these categories may involve distinctions unfamiliar to most people). In general, deeper hierarchies are more challenging to navigate than shallow ones and specific subcategories require a higher degree of cognitive effort than the basic categories described earlier.
Also, these specific subcategories may end up containing only a few items — not the end of the world, but not part of a robust content strategy either.
Approach 2: Leave Outliers Within the Main Category and Support Alternate Seeking Behaviors Through Metadata
As an alternative, you can leave those outlier category members within the slightly larger category that they normally would be a part of. This approach makes sense when the number of outliers is relatively small and they are close in family resemblance to the main category members.
There are a few reasons why this approach is sound in most situations:
- As indicated above, users’ mental category boundaries are not rigid, but based on degrees of family resemblance. Therefore, there is a good chance that they will still be able to locate the outliers placed in the bigger category.
- Because those outliers will be hosted in larger, more-heterogenous parent categories, they will be more discoverable (i.e., users who aren’t seeking those options out might stumble upon them as they parse through the category list).
- You can use alternate pathways to these outliers (e.g., robust search with a back-end taxonomy of concepts that can go into a much more structured category hierarchy) to support those users who won’t look for these outliers in their host category.
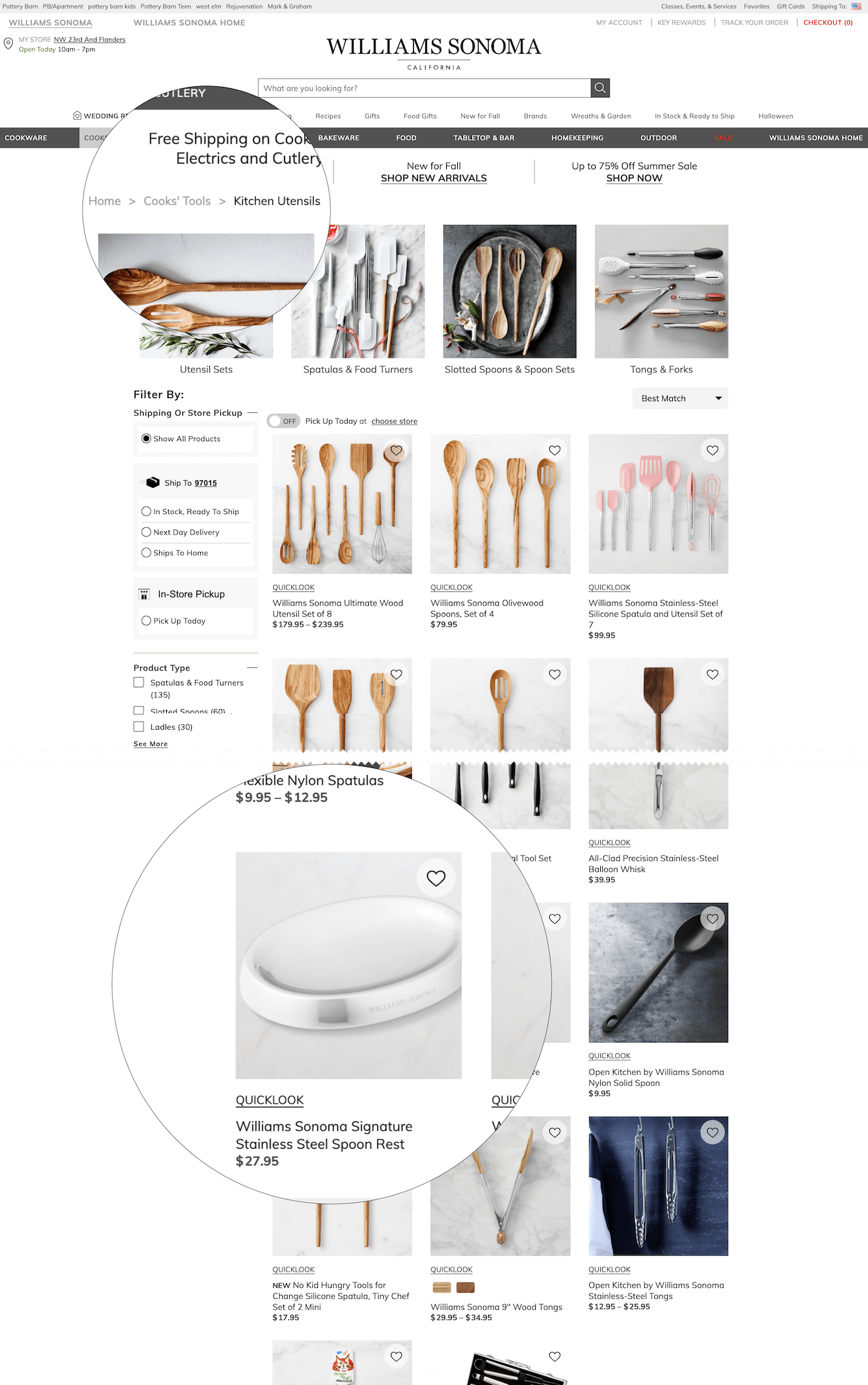
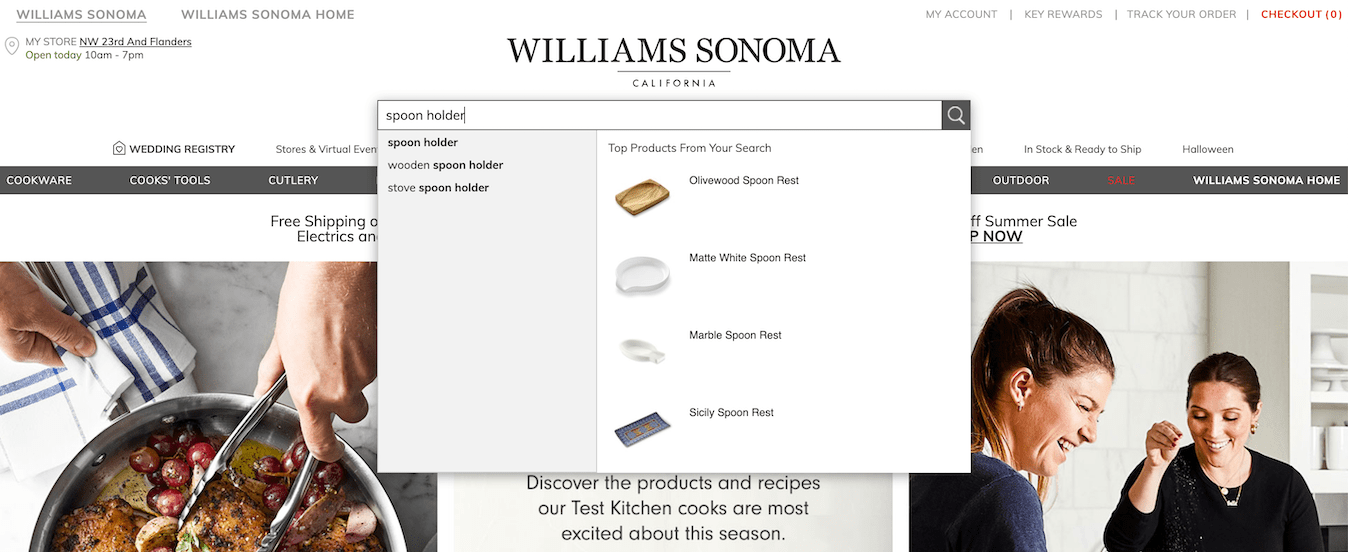
Approach 3: Polyhierarchy in Both Levels
Outliers can often be supported well by using both previous techniques — that is, by placing them in their own subcategory and in the main category. This technique has the same major limitation as creating a new subcategory for your outliers — you may end up with many sparsely populated, obscure subcategories.

Summary
Category outliers can be handled in multiple ways in information architecture. Creating separate, specific subcategories to house them often results in a mess of sparsely populated subcategories that are unfamiliar to users. In most cases, we recommend keeping the outliers within their larger category and assisting users with additional findability tools, such as search or faceted navigation.
References
Roger Brown. 1958. How Shall a Thing Be Called? Psychological Review 65:14-21
George Lakoff. 1987. Women, Fire, and Dangerous Things: What Categories Reveal about the Mind, University of Chicago Press, London.
Elanor Rosch. 1975. Cognitive representations of semantic categories. Journal of Experimental Psychology: General, 104, 192-233




Share this article: